Not long ago I was in a conference for high-performance computing where the "big guys" were talking about the future of computer architectures.
By now it is basically clear that there is no way, in the near future, to improve CPU's clock because of power and heating constraints. Everybody is going to multiple CPU's in a chip and multicores became the word of mouth and also a word to fear.
Whoever builds processors fear that multicore will not be able to bring a better user experience at our homes. Ohhh gosh, sales will go down, no volume, prices up and it will be the end of computer industry the way we know it. We must save it.
Computer architects think that if programmers were not so dumb they could write their code thinking in parallel and thinking a bit more in the computer architecture. Programmers are spoiled and the architects needed to put all the improvements transparent and dumb-proof. As programmers are so badly prepared for the task, somebody (maybe even us superior computer architects) will need to develop a layer that will abstract the parallelization complexity, taking advantage of several cores, saving the whole computing business and everybody will be happy ever after. We just can't really find out how.
Programmers do not give a damm for what computer architects think. They are a thousand abstraction layers above, over their java/perl/ruby virtual machines, creating applications, web-pages and database queries through some persistence layer and using high-level libraries.
I don't care about what sort of pieces my car engine is composed as far as the car goes well and gives me no trouble. I was very happy to get some extra performance without changing any piece of my code and this is the way I would like to keep being once I have much "real" work to do in order to keep my low-paid job anyway.
In-between we have the guys who develop middleware like compilers and libraries. And to these guys there is no money or recognition. Nor architects neither programmers really give much value to these guys. When was the last time you were asking yourself about which compiler to buy?
A middleware would be the solution to everybody and is the holy grail of computation nowadays. Everyone would like to build a compiler/library/run-time environment or any sort of layer that would enable not many or no change at all in the programs but would enable our software to scale in performance the more cores I have in my computer.
And it is funny to hear everyday a big company announcing they found the holy grail. Then you read about it and get into the details. This middleware is then either so limited or so hard to adapt your application or it just works for a couple of matrix multiplication implementations (exactly the ones they use for de demo).
My opinion is that this middleware does not exist such as we are searching for. This time we will need to rethink the way we do things and I believe this will happen from every layer simultaneously. From the hardware up to the VMs.
We are in a quite exciting moment where big players need to bet for their survival, where the old formula does not work anymore.
The "dumb" programmer whose software sells more if they use the multi-core computational power are, "surprisingly", adapting their applications and it works. Maybe programmers are not so dumb, they just follow the money, as anybody else.
Architects need to solve their computation bottlenecks and deliver more with every new processor generation. New levels of cache, different coherence protocols, placing new buses or changing them to use photons, using non-uniform memory access, stacking memory over the processor chip, reusing components through threads, or specializing the different cores.
In the middleware we have the traditional parallel computing libraries trying to go mainstream but failing, transactional memory, new innovative ways of simplifying working with threads. And money, quite some money, for the ideas that could unify it all in a simple and elegant way. Everybody is playing their cards and companies are financing the big universities and their own labs.
And you, what are you doing about it? Are you adapting your applications to the new era or just watching the battle?
Friday, August 29, 2008
Wednesday, June 11, 2008
MySQL and PostgreSQL performance comparison (using TPC-b based benchmark).
One of these recent days I was reading some feeds from MySQL planet and found this post comparing postgresql and mysql. Well, I found the post interesting, so I decided to do a little benchmarking of my own also, but this time with a workload based on the TPC-b benchmark. You can read more about this benchmark here. Basically, it is a stress test of the database back-end. From the description on the website: "TPC Benchmark B is designed to be a stress test on the core portion of a database system." Full specification is available here. In a nutshell, it is comprised of a single type of transaction that performs selects, updates and inserts on four distinct tables in the system: accounts, tellers, branches and history. The transaction profile is the following:
The runs conducted varied the number of costumers: 1,8,16,32,64. These represented the number of simultaneous clients that were actually emulated.
I configured PostgreSQL (8.3.1), using postgresql.conf, according to the following options:
As for MySQL (5.1.24-rc) I used the transactional storage engine InnoDb. Then I configured the engine according to the following options, in my.cnf:
With respect to the hardware, I used two nodes, one for executing the emulated clients (node A) and another to holding the databases (node B). The following table details the environment.
Both of the machines were dedicated, meaning that no other job was running concurrently with the benchmark. As for the network I am unable to claim the same, as the physical network was shared among people here in the lab accessing other servers. The benchmark implementation was developed within the context of the GORDA project and integrated into Bristlecone benchmarking framework, from Continuent.
So, taking into account the aforementioned settings, I performed several runs in which the difference among them was the number of concurrent connections opened to the database. From the runs, I have measured latency (ms - milliseconds) and throughput (TPM - transactions per minute). The samples from each of the runs were taken by droping the initial two minutes (avoiding the ramp up effects). Additionally, the outliers samples were removed by taking only the 98th percentile of set of samples. The results are depicted in the following two figures.


From these two figures, one may immediately conclude that the system is overloaded even when there are only eight clients in the system. This is predictable, since TPC-b does not add think time on transaction submission, hence the system is in overload. As a consequence the latency increases, due to queuing and the throughput remains stable. One interesting conclusion is that MySQL outperforms completely PostgreSQL in throughput. Since TPC-b is an update, stress test it seems reasonable to consider that MySQL is more suitable for workloads that characterized by update peaks.
What I would like to do next is to compare both of these DBMS using workload with more read operations (TPC-w?), and also compare them using some TPC-c based benchmark for modeling a more complex OLTP setting, and not a stressing it as TPC-b does. When I have the time, I will do this and let you know about the results.
UPDATE accounts
SET Abalance = Abalance + :delta
WHERE Aid = :Aid;
SELECT Abalance
INTO :Abalance FROM accounts
WHERE Aid = :Aid;
UPDATE tellers
SET Tbalance = Tbalance + :delta
WHERE Tid = :Tid;
UPDATE branches
SET Bbalance = Bbalance + :delta
WHERE Bid = :Bid;
INSERT INTO history(Tid, Bid, Aid, delta, time)
VALUES (:Tid, :Bid, :Aid, :delta, CURRENT);
The runs conducted varied the number of costumers: 1,8,16,32,64. These represented the number of simultaneous clients that were actually emulated.
I configured PostgreSQL (8.3.1), using postgresql.conf, according to the following options:
- max_connections = 100
- shared_buffers = 200MB
- effective_cache_size = 2GB
As for MySQL (5.1.24-rc) I used the transactional storage engine InnoDb. Then I configured the engine according to the following options, in my.cnf:
- innodb_buffer_pool_size = 500M
- innodb_flush_log_at_trx_commit=1
- innodb_thread_concurrency=0
- thread_cache_size=25
With respect to the hardware, I used two nodes, one for executing the emulated clients (node A) and another to holding the databases (node B). The following table details the environment.
| Node A | Node B | |
| CPU | Dual AMD Opteron(tm) at 1.5GHz | |
| Memory | 4 Gb | 3 Gb |
| Storage | One 55 Gb dedicated volume for each node (RAID5). | |
| Network | Ethernet: 1 Gbps | |
| Operating System | Ubuntu 7.10 | |
Both of the machines were dedicated, meaning that no other job was running concurrently with the benchmark. As for the network I am unable to claim the same, as the physical network was shared among people here in the lab accessing other servers. The benchmark implementation was developed within the context of the GORDA project and integrated into Bristlecone benchmarking framework, from Continuent.
So, taking into account the aforementioned settings, I performed several runs in which the difference among them was the number of concurrent connections opened to the database. From the runs, I have measured latency (ms - milliseconds) and throughput (TPM - transactions per minute). The samples from each of the runs were taken by droping the initial two minutes (avoiding the ramp up effects). Additionally, the outliers samples were removed by taking only the 98th percentile of set of samples. The results are depicted in the following two figures.


From these two figures, one may immediately conclude that the system is overloaded even when there are only eight clients in the system. This is predictable, since TPC-b does not add think time on transaction submission, hence the system is in overload. As a consequence the latency increases, due to queuing and the throughput remains stable. One interesting conclusion is that MySQL outperforms completely PostgreSQL in throughput. Since TPC-b is an update, stress test it seems reasonable to consider that MySQL is more suitable for workloads that characterized by update peaks.
What I would like to do next is to compare both of these DBMS using workload with more read operations (TPC-w?), and also compare them using some TPC-c based benchmark for modeling a more complex OLTP setting, and not a stressing it as TPC-b does. When I have the time, I will do this and let you know about the results.
Saturday, May 31, 2008
GORDA: the day after!
May 30th officially marks the end of the GORDA project. I had the privilege to be involved in it from the very beginning. I was there in the kickoff meeting, back in October 2004, and I was there in the last review meeting, last Friday. Both of these two meetings took place in Braga at University of Minho.
In this last review, everything went smooth. Nevertheless, I have to stress one of the project deliverables, the prototype demonstration. It was a live prototype demonstration of a replicated database using all GORDA software packages. The demo happened without any glitch whatsoever and I actually felt very proud as I watched all concepts and ideas, that we have had for the past three and a half years, implemented, deployed and executing nicely for the reviewers.
This demonstration presented two different replication scenarios: i) Sequoia+MySQL based master-slave replication; ii) PostgreSQL based, multi-master update everywhere replication using certification and additional autonomic cluster management tools. Pretty much all the software developed is hosted or referenced in GORDA website, so If you just feel curious, feel free to sneak a peak. We have GORDA implementations for PostgreSQL, MySQL (roughly), Sequoia and Apache Derby. Not all of them implement the fully GAPI (GORDA API) set as defined in the API reference, but still they show that the concept/model is feasible.
Now that the project is over, I am wondering what will happen with GORDA legacy. I believe that at least one of the project partners, will merge GORDA contributions into some of their products. As for the rest of the open source database communities, I am still not sure what is the impact of GORDA on their concerns about replication. Well, at least in the long run it is not clear. Currently, every time I engage in some database replication discussion (outside academia circles) the speech almost instantaneously includes "master-slave" expression. It is kind of like a tunnel vision around primary-backup replication. People are in this mindset for a long time, and it is hard to make them understand that there are other ways of doing things (eventual with a different kind of trade-offs). Regarding GORDA, I sometimes am afraid that after preaching to people about GAPI they would just get back to me with something similar: " - So... Can we do master-slave on top of it?". Probably, the industry is not ready for anything different yet... I mean, GORDA has prototypes on multi-master update everywhere replication using certification, although sub-optimal they are proof-of-concept implementations. They prove the very feasibility of these "other" approaches. So I guess my question is: "If you are a database replication solution provider, would it be interesting for you to have other solutions than master-slave replication (for instance: row based, no data partitioning, master-master replication)? Apart from very specific situations, Is there any user demand for anything other than primary-backup?"
Personally, I believe that some of GORDA ideas will make it into the market, but to what extent and within which time-frame is not that clear for me. If at least GAPI model gets embraced by open source databases (PostgreSQL, MySQL and Apache Derby) it will be a major achievement and a major break-through. Honestly, I like to think that last demonstration we did on Firday, was actually the first of many others. Additionally, I will continue to maintain and support parts of the GORDA software, either because I need them (in my PhD thesis for instance) or because I have sensed some interest from the community (which has already resulted in a trip to California for me and Alfrânio to present some of this at MySQL Conference).
By now, if you are still reading this post, you should check GORDA website for details and software. The public deliverables with all the documentation eventually will have their final versions uploaded and published, but the software is already available. Feel free to provide some feedback, and if you have anything to add in the part of the user demands with respect to other solutions than master-slave replication I would be delighted to know about them.
Final remark: inevitably, GORDA's end felt like we had "finished writing a book", but also that we "had began writing a new one."
In this last review, everything went smooth. Nevertheless, I have to stress one of the project deliverables, the prototype demonstration. It was a live prototype demonstration of a replicated database using all GORDA software packages. The demo happened without any glitch whatsoever and I actually felt very proud as I watched all concepts and ideas, that we have had for the past three and a half years, implemented, deployed and executing nicely for the reviewers.
This demonstration presented two different replication scenarios: i) Sequoia+MySQL based master-slave replication; ii) PostgreSQL based, multi-master update everywhere replication using certification and additional autonomic cluster management tools. Pretty much all the software developed is hosted or referenced in GORDA website, so If you just feel curious, feel free to sneak a peak. We have GORDA implementations for PostgreSQL, MySQL (roughly), Sequoia and Apache Derby. Not all of them implement the fully GAPI (GORDA API) set as defined in the API reference, but still they show that the concept/model is feasible.
Now that the project is over, I am wondering what will happen with GORDA legacy. I believe that at least one of the project partners, will merge GORDA contributions into some of their products. As for the rest of the open source database communities, I am still not sure what is the impact of GORDA on their concerns about replication. Well, at least in the long run it is not clear. Currently, every time I engage in some database replication discussion (outside academia circles) the speech almost instantaneously includes "master-slave" expression. It is kind of like a tunnel vision around primary-backup replication. People are in this mindset for a long time, and it is hard to make them understand that there are other ways of doing things (eventual with a different kind of trade-offs). Regarding GORDA, I sometimes am afraid that after preaching to people about GAPI they would just get back to me with something similar: " - So... Can we do master-slave on top of it?". Probably, the industry is not ready for anything different yet... I mean, GORDA has prototypes on multi-master update everywhere replication using certification, although sub-optimal they are proof-of-concept implementations. They prove the very feasibility of these "other" approaches. So I guess my question is: "If you are a database replication solution provider, would it be interesting for you to have other solutions than master-slave replication (for instance: row based, no data partitioning, master-master replication)? Apart from very specific situations, Is there any user demand for anything other than primary-backup?"
Personally, I believe that some of GORDA ideas will make it into the market, but to what extent and within which time-frame is not that clear for me. If at least GAPI model gets embraced by open source databases (PostgreSQL, MySQL and Apache Derby) it will be a major achievement and a major break-through. Honestly, I like to think that last demonstration we did on Firday, was actually the first of many others. Additionally, I will continue to maintain and support parts of the GORDA software, either because I need them (in my PhD thesis for instance) or because I have sensed some interest from the community (which has already resulted in a trip to California for me and Alfrânio to present some of this at MySQL Conference).
By now, if you are still reading this post, you should check GORDA website for details and software. The public deliverables with all the documentation eventually will have their final versions uploaded and published, but the software is already available. Feel free to provide some feedback, and if you have anything to add in the part of the user demands with respect to other solutions than master-slave replication I would be delighted to know about them.
Final remark: inevitably, GORDA's end felt like we had "finished writing a book", but also that we "had began writing a new one."
Friday, April 25, 2008
MySQL Users Conference 2008
Yeah !!! We win a trip to California after working too hard on a replication plugin for MySQL.
It was a 30 hours journey to arrive in California. The goal was to attend the MySQL Users Conference and show ideas developed in the context of the GORDA Project.
Mission accomplished my friends.
Me and my Friend Luis met a lot of interesting people and had passioned discussions on replication. Unfortunately, there was no much time to attend talks even the one given by Werner Vogels. There were more than 2000 people thinking on MySQL, learning a little bit more on it, doing business, doing contacts and hiring people. I was not expecting such atmosphere: everyone was breathing MySQL. Even the competition was attend the conference. There were many guys from Microsoft, IBM and Oracle.
In our spare time, we went to San Francisco to see the Golden Gate and Alcatraz. While driving through the street of Santa Clara, Palo Alto, etc, etc we came across buildings from important enterprises such as Google, IBM, Yahoo, Oracle, Microsoft and from important universities such as Berkley and Standford.
Nice trip, but I am afraid that I got excited for driving a Mustang as I did not pay attention to the traffic lights. Most likely my next credit card bill will give me a stroke.
Cheers.
It was a 30 hours journey to arrive in California. The goal was to attend the MySQL Users Conference and show ideas developed in the context of the GORDA Project.
Mission accomplished my friends.
Me and my Friend Luis met a lot of interesting people and had passioned discussions on replication. Unfortunately, there was no much time to attend talks even the one given by Werner Vogels. There were more than 2000 people thinking on MySQL, learning a little bit more on it, doing business, doing contacts and hiring people. I was not expecting such atmosphere: everyone was breathing MySQL. Even the competition was attend the conference. There were many guys from Microsoft, IBM and Oracle.
In our spare time, we went to San Francisco to see the Golden Gate and Alcatraz. While driving through the street of Santa Clara, Palo Alto, etc, etc we came across buildings from important enterprises such as Google, IBM, Yahoo, Oracle, Microsoft and from important universities such as Berkley and Standford.
Nice trip, but I am afraid that I got excited for driving a Mustang as I did not pay attention to the traffic lights. Most likely my next credit card bill will give me a stroke.
Cheers.
Are people afraid of group communication or fault tolerance is not important nowadays?
March was a hell of a month and April started exactly as March: almost 7 per 7 and 12 hours per day on a replication plug-in for MySQL. I hope that this hard work ends up with a prize: a trip to California for the MySQL Users Conference and enough euros to buy me a boat. Despite this strenuous but delightful effort, my friend Eduardo has kept asking me to write something in the blog. I still can hear his words: "We should write frequently... Luis have written something, I have... So, it is your turn". So, I took my spear time from 3 a.m from 7 a.m to start writing something...
In fact, I have already started writing three different posts but I have not had time to finish none. One of them is a joint work with Luis, and the subject is quite good. Wait and see. But this post, I started writing from scratch and is about something that is bothering me for a while and today the issue was raised again: "Why people don't use the main concepts on group communication?"
Roughly, a group communication toolkit provides a set of primitives to send messages to and receive from a group of peers (i.e. hosts) and manages which peers are in the group, thus providing information when a member joins or leaves the group spontaneously or due to a crash.
Let us however reduce the scope of this question as I don't have much time: "Why people don't take into account consensus and in particular group membership algorithms when they design fault tolerant applications?" Don't think I am lousy writer... I don't know... Maybe I am... But as this is my spear time, I am writing and at the same time drinking a bottle of wine and I am getting more and more relaxed...
Of course, the distributed system community uses group communication and knows that consensus is a fundamental problem. I am asking about other communities such as those involved in building database and parallel system. Such communities usually try to come up with fault tolerant applications or high availability solutions that don't properly take into account group membership, for instance. Don't understand this statement as a personal opinion. I've been seeing different cases. When these communities need functionalities that might be provided by a group communication infra-structure, such as group membership, they develop their own stuff without taking into account important concepts such as consensus. Unfortunately, not doing that means bugs that are hard to trace as there are several corner cases (e.g. failures while dealing with previous failures) that must be properly handled.
Most likely, this is time for an explanation on consensus and group membership. Why group membership is important for fault tolerant applications?
The group membership monitors which members are active in a group and designing it in a naive way may have unfortunate consequences.
For instance, build a group membership service solely based on a heart beat approach that waits for periodic messages from peers is not a good idea as a burst in the network may lead peers to think that others are dead. Of course, a "smart developer" has already thought about that and before assuming that a pear is dead he/she would try to contact it again. But for how long should he/she keep trying to? Does he/she should wait for a TCP-IP timeout connection before giving up ? Most likely this is not a good idea because it may take hours regarding the type of failure. Due to congestion problems a peer may think that one is dead and the others may not. In this case, the same "smart developer" may come up with a voting protocol that collects information from other peers before kicking one out. This may work in most cases but suppose that during the voting process the pear that was responsible for collecting votes and deciding fails? And now?
To properly circumvent these corn cases, one will eventually end up with a group membership solution which needs a consensus protocol to achieve decisions on which peers are operational. Any naive attempt to circumvent these problems may end up with a case that was not taking into account and therefore may generate unfortunate consequences: bugs and bugs and bugs that are hard to trace.
Does this happen because the distributed system community is not good enough to disseminate what their know? Does this happen because other communities are only looking at their belies? Does this happen because group communication is still complex after all these years? Yeah, group communication is not a simple subject but neither b-trees and nobody consider developing a database (not a main-memory or in-memory database) without taking into account b-trees and their complex algorithms for concurrency and recovery.
Most likely, such theories are not applied in practice because there is no group communication toolkit ready to be deployed. I agree that are none but at the same time I believe that different applications require group communication protocols tailored for their needs and in my opinion developing a group communication toolkit is simpler that developing a full-fledged b-tree implementation. At least this is my biased opinion.
So I have this question if group communication is so great why other communities don't give enough attention to this subject? Please, give me answers.
Wednesday, April 23, 2008
Anouncements: JOIN 2008 cancelled and talk at UAB
It is really a pity and unfortunate that the JOIN 2008 event was canceled. I was preparing a talk with the idea of having content and fun, something different than traditional so it would not be boring and, most of all, put students to think about and, if possible, discuss the topic.
I was having lots of fun preparing it. The idea was it to be presented like a fairy tail (suited to the title). The index was called "Once upon a time..." and the first theme was "Chapter One: When the princess became a frog" where I would talk about my first experience with software engineering in a huge software development where all the aspects of engineering were imposed by the contract and our consulting company had no engineering culture in the software field. Well, the result is that instead of being helped by the process I felt we would be far more productive without it (or with a different use of it). The software engineering princess (I know in the tale it is a prince but I rather prefer a princess myself) became a heavy frog :)
Anyway. The event as well as the talk are canceled. I wish the organization board more luck next time.
In the meantime I was invited for a talk at Universidad Autonoma of Barcelona about Post-Doc. The idea is to talk about my experience and how I see a post-doc. Title is:
I was having lots of fun preparing it. The idea was it to be presented like a fairy tail (suited to the title). The index was called "Once upon a time..." and the first theme was "Chapter One: When the princess became a frog" where I would talk about my first experience with software engineering in a huge software development where all the aspects of engineering were imposed by the contract and our consulting company had no engineering culture in the software field. Well, the result is that instead of being helped by the process I felt we would be far more productive without it (or with a different use of it). The software engineering princess (I know in the tale it is a prince but I rather prefer a princess myself) became a heavy frog :)
Anyway. The event as well as the talk are canceled. I wish the organization board more luck next time.
In the meantime I was invited for a talk at Universidad Autonoma of Barcelona about Post-Doc. The idea is to talk about my experience and how I see a post-doc. Title is:
Postdoc: useful, necessary ... or a waste of time?It will take place in the Computer Architecture and Operating Systems department at UAB, May 9th at 12:30. More information here.
Friday, April 4, 2008
Anouncement: Talk at JOIN 2008
Hi there, I will be giving a talk at JOIN ("Jornadas de Informática") in Braga, Portugal on May 1st. If you are around and want to "JOIN", be my guest (don't forget to talk with the organization team before :-) ).
The talk will be on Software Engineering.
This will be a great challenge for me once I am not an expert in software engineering although I have been deploying software for at least 10 years now.
I decided to take the risk and talk about my personal experience. I think students have their professors to talk about theories but experience is different, especially in software engineering that is so "not" used everywhere.
The title of the talk is:
The talk will be on Software Engineering.
This will be a great challenge for me once I am not an expert in software engineering although I have been deploying software for at least 10 years now.
I decided to take the risk and talk about my personal experience. I think students have their professors to talk about theories but experience is different, especially in software engineering that is so "not" used everywhere.
The title of the talk is:
Werewolves, little red riding hood, software engineering and other fairy tales: my personal experience in 10 years at the “software development” field.There it goes a short abstract.
Over the last 10 years I worked on the developing of database applications in an IT Consulting Company in Brazil; managing the development of an ERP system; warehouses and ETL systems in the IT department of a Communication Group in Brazil; deploying scientific applications for my PhD and post-doc in the different cultural environments of Spain and Germany. Nowadays I work at HP Labs doing research on the development of a full-system execution-driven simulator for massive clusters of massive cores. Where and how did software engineering interact with my personal work? How close is software engineering to the traditional engineering? Or is it a long and elaborate fairy tale? What is my personal opinion about it? What am I using now and where I would like to get? This talk is about a one-man experience and his believes of software engineering, computer systems and a bit more.I hope it will be interesting and fun.
Friday, March 28, 2008
“To the infinite and beyond”[1] or Who on Earth needs several cores at his desktop?

In 1965 Gordon Moore published his paper "Cramming more components onto integrated circuits" and became famous by what is called Moore’s law. Moore’s law states that the amount of transistors of a computer processor doubles every 2 years[2]. In this paper he predicts a whole revolution in computing and communication that would be caused by the integration, like the advent of home computers or cell phones (the picture above, taken from his paper, illustrates that):
"Integrated circuits will lead to such wonders as home computers—or - at least terminals connected to a central computer - —automatic controls for automobiles, and personal portable communications equipment".
Moore was very successful with his statement especially because the amount of transistors is also related to every other computer metric such as processors’ performance for example. If I had read this article in 1965 I would have thought mathematically and reasoned that this integration could not be sustainable for quite long. Moore also thought that and this prediction was just for the following 10 years, in other words, until 1975.
To understand
I say better because processors’ performance did grow proportionally with its integration not just because of faster clock cycles but mainly because we used the extra transistors in amazing architectural improvements on pipelining, super-scalars, branch prediction, and etc.
But what
I can imagine myself, in late 60's talking to some “mates”:
- What do you think of Gordon’s paper? – I would have asked
- Well, in 10 years we may reach 32 times more transistors. It seems feasible – somebody would have said.
- What if we can keep this for, let’s say, the next 40 years at least? What if computers could be really found at every desk? – I wish I would have said this :-)
- Wow –someone would say – but this would mean 1,000,000 times more transistors. And, of course, tons of computers.
- Imagine the performance growth, the memory growth, …
- But – there is always a skeptical – who on Earth would need that much performance at his desk?
So, from the time
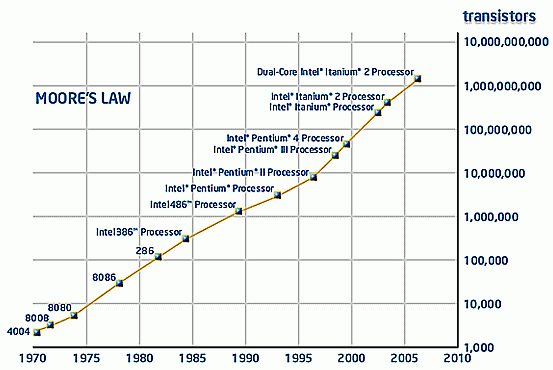
The fact is that computers got faster and applications got far more complex, not necessarily in this order. We use today the computer for applications that would have been unthinkable decades ago by the simple fact that they just could arise now, when we have the right conditions.
By now you might be asking yourself where I want to get. Well, my dear reader, for a series of reasons (power limitations, heat, …) processors industry decided to use the extra transistors to put more than one processor, or core, in a chip. Multi-cores are now the fashion of computer architecture and everybody is discussing about it. It is certainly a big turn of direction.
Cores per processor are growing (2, 4, 6, 8, 16 …) and advancing to the desktop. Some people then started asking for how long? How many cores can we use in the desktop? Who on Earth will need so many cores at the desk?
And this is exactly the point. Most of today’s applications are not really able to take advantage of several cores. Does this mean that we did reach the point we do not need to buy new computers? Will I be happy for several years with my 6 core computer? Will computer industry finally slow down on computer sells?
Some people think so but I disagree. I believe it is just a matter of time for current applications to start multi-threading everywhere and give some use for our cores. But this, in my opinion, will not be the reason we will buy next generations hardware. I believe a whole set of new applications will arise just because today we have all this processing power “for free”. Applications we may just imagine today and applications we can not yet think about. Really good speech transcriptors (I would not need to type this post), image recognition and photo/videos image searching. What about asking the computer for all the videos, pictures and documents where your child is present? What about the ones where the day was sunny? Your laptop will drive your car, based on the traffic info, while you are dictating a memo.
Either multi-cores will slow down computer industry and we will be satisfied for longer with our desktop computers or the race will keep going and new amazing hardware and software will emerge. The third possibility is the advent of a totally different model of computer business. Choose your future scenario and tell me your opinion.
I am not good at all in “futurology” but I believe cores are here to stay and programmers will make their way to use them giving us different types of functionalities we did not even know we wanted but we will not be able to live without. And this technology race will keep on going.
For how long? For at least a couple of decades when the business might change.
Where is the limit? “The infinite and beyond”.
[1] Buzz Lightyear in ToyStory
[2] Initially he said every year but then he backed up and stated it would double every couple of years.
Wednesday, March 19, 2008
Aurora!
Do we really need another blog about computers, technology, software architecture?
I mean, seriously... If we take a look at some on-line blog statistics, we get astonished with the amount of information that is published on a daily basis. Nevertheless, we feel that there is still some room for our opinions and we really like rambling about our favorite subjects: databases, transaction processing, data replication, clusters, distributed and parallel systems. Even if these topics are not matters of regular conversations, we think that they still conceal a whole range of interesting problems that should be reasoned about.
Despite the fact that there are several websites, blogs, forums on these same subjects, in which important people from academia and industry express their opinions, we believe that this one can make a difference. The key point is that we are not seeking fame by publishing scientific papers on these matters, though it happens, or becoming a successful entrepreneur with a fat bank account and a product to sale (not that having such a bank account would not be a nice thing). As such, the content presented in this site is biased only by our knowledge and our passion. And yes, passion may even blind us, but you are more than welcome to ring the bells and sound the alarm. Most often these matters come into our minds, either because they are related to our work or just because it happened, and we drift aimlessly between thoughts and theories.
A little note about ourselves:
- We believe that there are so many wonderful things other than computer science and we really enjoy them;
- Though we are not genius, enlightened or bright people, we are not dummies also (at least we like to think that we are not);
- Also, we are not techies or computer geeks, we just like a good discussion.
Anyway, we want this to be an enjoyable ride, sometimes with new and exciting ideas, others with controversial points of view, raising the tone of criticism. We are departing to an uncharted parallel universe in which free thinking and free speech are brought together in a perfect synergy, and guess what... we want company. We are at the shores of a knowledge ocean and we have just started to dip our toes in it.
As of what it is to come... should we say: "Here be dragons" ? Most certainly. Jump in. Criticize us. Make us pointless by debating our ideas and not by ignoring them. After all... We hope to learn from you much more than you will be learning from us. This is our master-plan.
I mean, seriously... If we take a look at some on-line blog statistics, we get astonished with the amount of information that is published on a daily basis. Nevertheless, we feel that there is still some room for our opinions and we really like rambling about our favorite subjects: databases, transaction processing, data replication, clusters, distributed and parallel systems. Even if these topics are not matters of regular conversations, we think that they still conceal a whole range of interesting problems that should be reasoned about.
Despite the fact that there are several websites, blogs, forums on these same subjects, in which important people from academia and industry express their opinions, we believe that this one can make a difference. The key point is that we are not seeking fame by publishing scientific papers on these matters, though it happens, or becoming a successful entrepreneur with a fat bank account and a product to sale (not that having such a bank account would not be a nice thing). As such, the content presented in this site is biased only by our knowledge and our passion. And yes, passion may even blind us, but you are more than welcome to ring the bells and sound the alarm. Most often these matters come into our minds, either because they are related to our work or just because it happened, and we drift aimlessly between thoughts and theories.
A little note about ourselves:
- We believe that there are so many wonderful things other than computer science and we really enjoy them;
- Though we are not genius, enlightened or bright people, we are not dummies also (at least we like to think that we are not);
- Also, we are not techies or computer geeks, we just like a good discussion.
Anyway, we want this to be an enjoyable ride, sometimes with new and exciting ideas, others with controversial points of view, raising the tone of criticism. We are departing to an uncharted parallel universe in which free thinking and free speech are brought together in a perfect synergy, and guess what... we want company. We are at the shores of a knowledge ocean and we have just started to dip our toes in it.
As of what it is to come... should we say: "Here be dragons" ? Most certainly. Jump in. Criticize us. Make us pointless by debating our ideas and not by ignoring them. After all... We hope to learn from you much more than you will be learning from us. This is our master-plan.
Subscribe to:
Posts (Atom)